Week 19
Cleaning up data pt. 2
So, instead of using R to go back and calculate summary statistics, Rebekah, my CREU partner actually developed some C# code that scrapes all the transcripts, gets the lines with timestamps and then determines things like number of tokens, number of unique tokens, duration of speech within the session, etc.. Shouts out to her! Her work saved me. You can check out her blog here for more details about the script:
$ less Bernstein_Children_Alice_alice1.txt
Age: 1;1.0
Sex: Female
Total Number of words: 508
Number of Unique words: 176
...
...
MLU: 2
MLW: 3
Total time in seconds: 648.872
open 0_9901
there are so many toys 9901_16871
oh mama too many toys 16871_19086
okay 19086_22167
was that good funny eating noise 22167_24382
do these squeak 24382_25894
no 25894_26571
there 26571_28461
build (th)em up 28461_29938
okay 29938_31931
what 31931_34564
take them down 34564_36791
...
Now, I can use the .txt files she generated to create the associated audio segments:
.
.
.
if totalNumberOfFiles >= 1
for k = 1 : totalNumberOfFiles
% Go through all those files
thisFolder = allFileInfo(k).folder;
thisBaseFileName = allFileInfo(k).name;
fullFileName = fullfile(thisFolder, thisBaseFileName);
% Open and read the transcript
% Note: This converts the transript file to a text file
fileText = fileread(fullFileName);
NewFolder = strrep(thisBaseFileName, '.txt', '')
% Get the location of the audio file associated with the transcript file
audioLocation = strrep(strrep(fullFileName, '_', '/'), '.txt', '.wav');
audioLocation = insertAfter(audioLocation,'Children','/0wav') %0wav is for folders that contain 0wav (must be manually changed atm)
% Check if audio file exist
if(exist(audioLocation,'file') > 0)
% Create a directory to store the audio segments
mkdir(NewFolder)
cd(NewFolder)
% Read in the audio file
[x,Fs] = audioread(audioLocation);
% Note: Unicode Character 'BULLET': U+2022/char(8226) is not sufficient
expr_TS = '[0-9]+_[0-9]+';
% Get timestamps from transcripts
matches = regexp(fileText, expr_TS,'match');
% Get start and stop times from matches...
for i = 1:length(matches)
num = textscan(string(strrep(matches(i),'_', ' ')),'%f', 'Delimiter',' ');
num = num2cell(permute(num{1},[2,1]));
num = cell2mat(num);
st = num(1); % start time in milliseconds
et = num(2); % end time in milliseconds
if(st == 0) % MATLAB indexes starting from 1
st = st + 1;
end
startTime = round((st/1000)*Fs); % segment starting frame
endTime = round((et/1000)*Fs); % segment end time frame
if(endTime > length(x)) % Make sure endTime doesn't go over!
endTime = length(x);
end
segment = x(startTime:endTime); % get audio segment from audio file
% Generate name for output file
i = num2str(i);
i = insertBefore(i,i,'_');
outputFileName = strcat(i,'.wav');
outputFileName = strrep(thisBaseFileName,'.txt', outputFileName);
% Output audio file
audiowrite(outputFileName,segment,Fs);
end
cd ..
else
disp('audio file(s) does not exist');
AccumulatedTranscripts = [AccumulatedTranscripts; {thisBaseFileName}];
end
end
end
% Output all the odd transcript files
dlmcell('OddAudio.txt', AccumulatedTranscripts);
For clarity, the above code generates a .wav file for each audio segment within the transcript. Here is a plot for visualizing this process:
% Read in audio file and generate plots for an audio file and a audio file segment
[x,Fs] = audioread(audioLocation);
[M,N] = size(x);
dt = 1/Fs;
t = dt*(0:M-1);
segments = xlsread('timestamps.xlsx','A1:B1'); % example uses an excel file that contain the timestamps
L = size(segments,1);
% Plot entire audio file
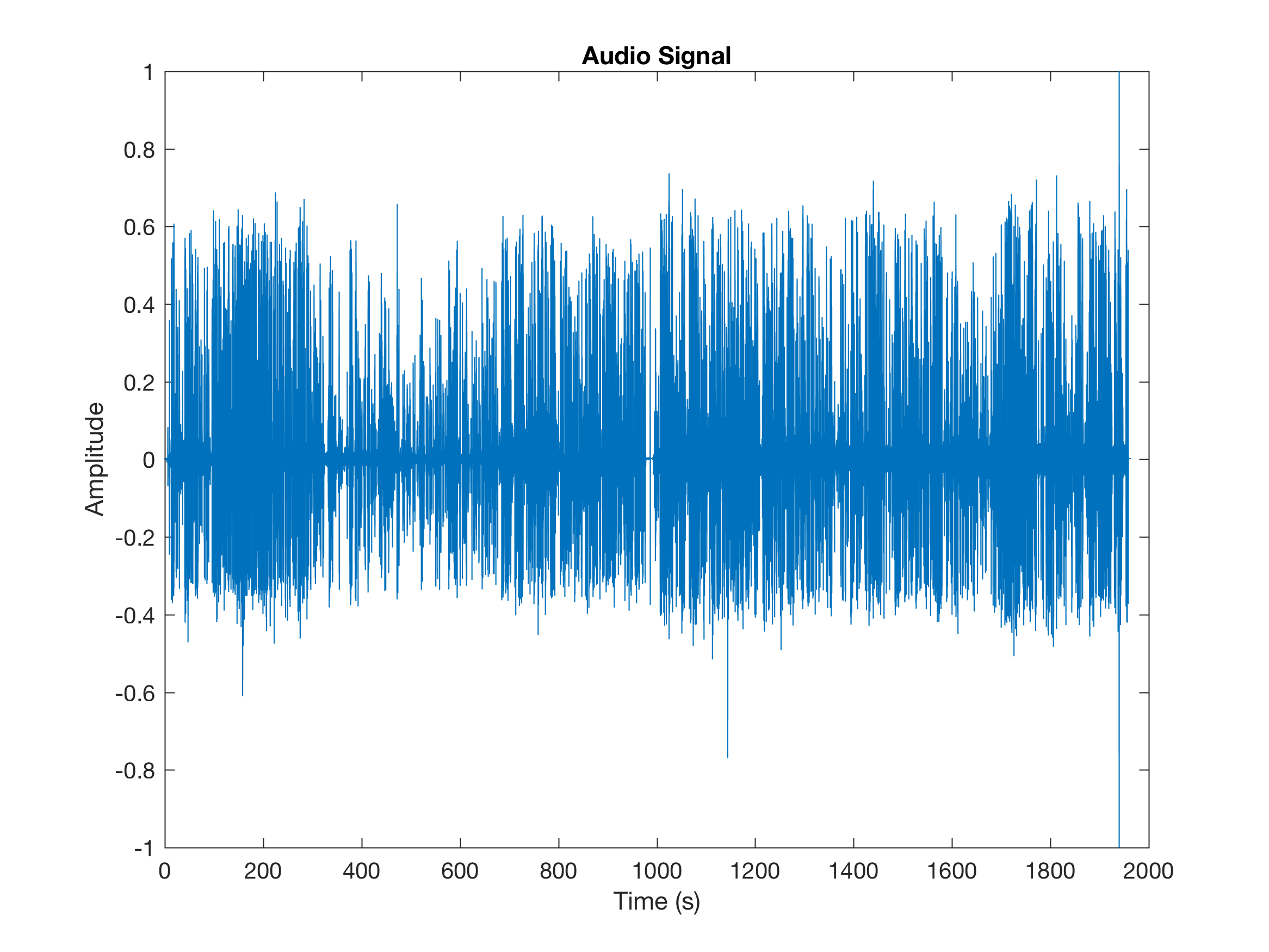
figure;
plot(t,x);
title('Audio Signal');
xlabel('Time (s)');
ylabel('Amplitude');
% Plot audio segment
idx = (segments(1,1) < t ) & ( t < segments(1,2)) ;
figure;
plot(t(idx),x(idx));
title('Audio Signal-Segment');
xlabel('Time (s)');
ylabel('Amplitude');
MATLAB OUTPUT: full audio file
MATLAB OUTPUT: segmented audio file
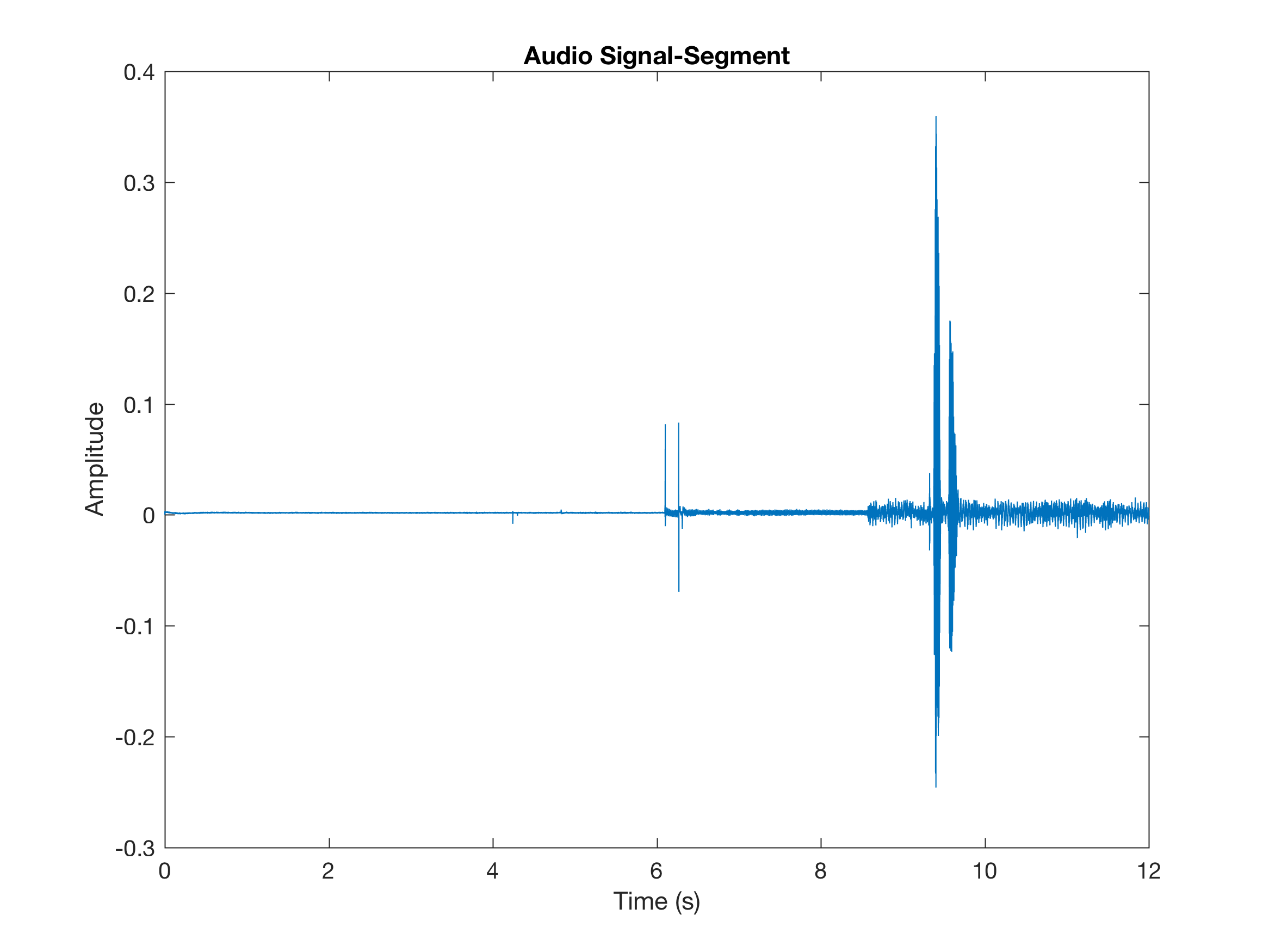
The majority of the above code uses a combination of MATLAB regular expression functions and audio tools. Turns out this was a conceptually easy problem, but difficult to get all the parts together. I was actually playing around with ffmpeg, trying to extract the audio segments of interest. It’s actually pretty straightforward:
$ ffmpeg -i alice1.wav -ss 0 -t 9.901 -acodec copy alice-segment1.wav
However, I’m very picky… I mean, I’m still trying to get comfortable with MATLAB again. Though, it would be good practice to make use of bash scripts. I don’t think my MATLAB method is the most accurate way of getting the audio segments but I think it’s a pretty good solution. Comparable to most methods.
Additionally, I think it’s a good idea to analyze the audio segments for their signal-to-noise ratio (SNR). Signal-to-noise ratio is defined as the ratio of the power of a signal (meaningful information) and the power of background noise (unwanted signal).
Which means, if the SNR across the corpus is low, then I think we have a problem. However, if the SNRs are reasonable values (or perhaps we can even throw away the files that have poor SNRs), then the corpus is probably fine. This came out of realizing that the time stamps don’t correspond to the start and stop time of words, but rather the duration of the entire utterance. For example, the first utterance in the alice1.wav last from 0 to 9.9901 seconds. However, only one word is uttered, ‘open’, and it’s at the end of the duration. Thus, there is more noise than signal in that 10 second clip. In general, that could be problematic for training.
As an example, we will calculate the SNR of the alice1.wav file:
% Calculate SNR
snr(segment)
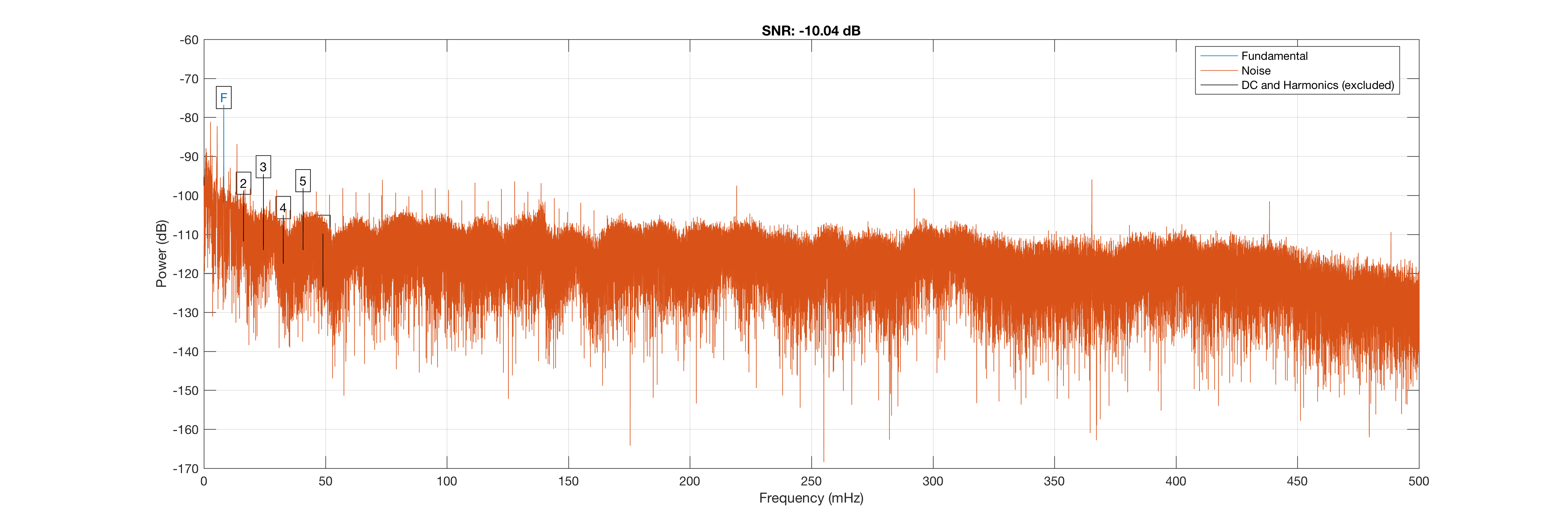
Cool! Super straightforward and MATLAB automatically generates a nice plot of the SNR. Note: We typically get SNR in values of dB (logarithmic decibel):
Kind of cool, I do think SNR will help explain some of the variation we get when we test our ASR system.
< -10 dB isn’t very good (the closer it is to 0 the better), but it’s not terrible. So, that might be an interesting analysis in of itself, but at the moment, I think it’s more interesting that negative. I’ll have to scrape through all the files to asses how SNRs are distributed across the corpus.
Best,
EO