Week 32
Presentation notes pt.1
The 2018 KU symposium is in two weeks, so I decided to start outlining my presentation. I only have 10 minutes to talk, so again the goal is to make the research as simple and as profound as possible. You know, high-level messaging through simple clean digestible powerpoint slides.
In fact, I’ve taken my speech concept slides and CogSci 2018 outline slides and melded them together to give myself a nice outline. I actually presented these slides to Dr. Brumberg and Rebekah this week. Though, because they’ve already seen most of these slides, we mostly talked about what I should and shouldn’t present. For example, avoid talking about how computing systems (artificial intelligence) is and will continue to manage a weird amount of human life…
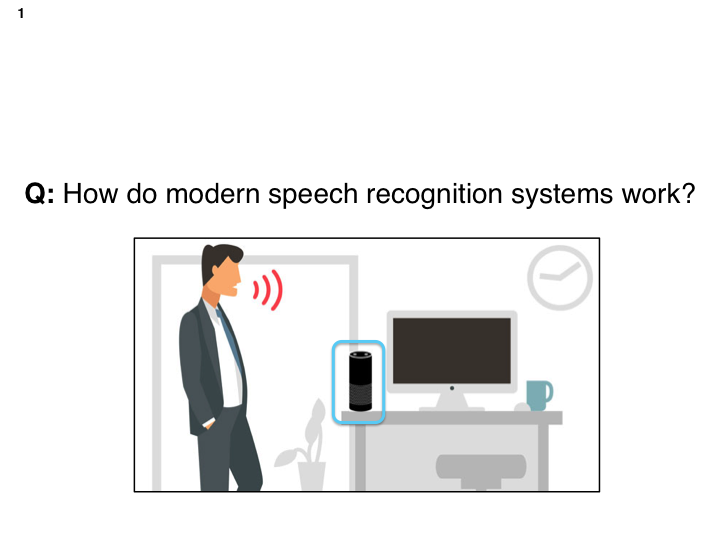
The Amazon Echo (Alexa) is a great example of a modern day speech recognition system. These systems help us play music, make reservations, and schedule events in our lives.

These speech recognition systems are pretty robust and typically human-to-computer speech recognition is pretty accurate. That is, most of the time Alexa will recognize your speech.
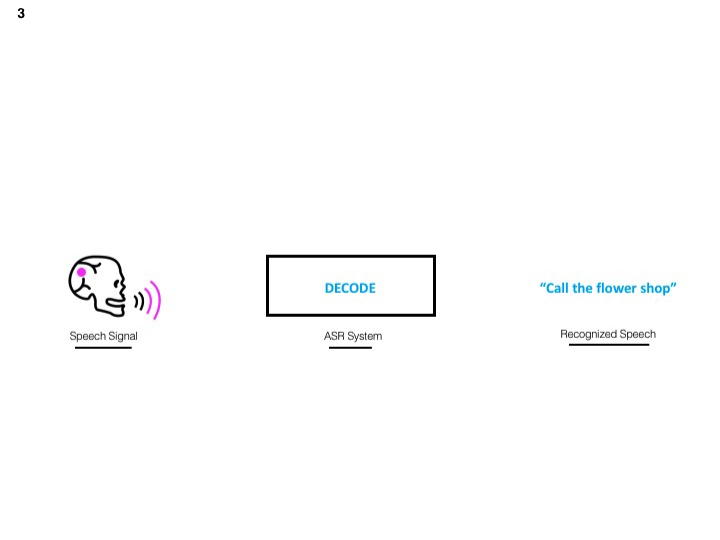
Within all speech recognition system is the decoder. The decoder is thing doing the heavy lifting.
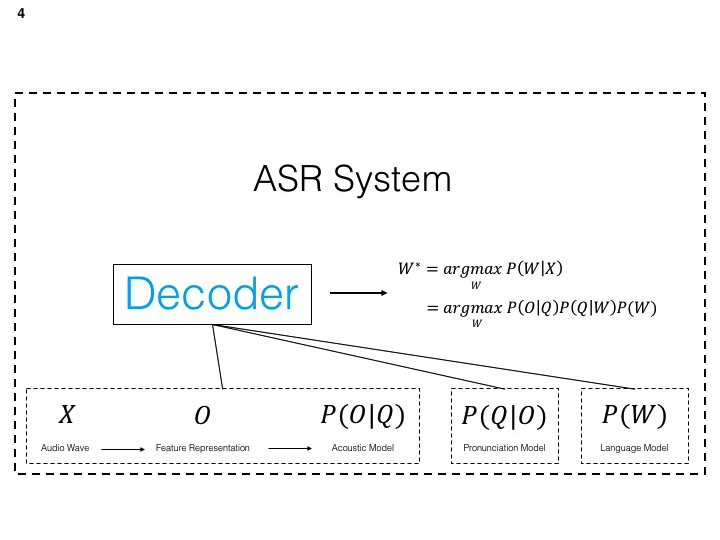
On further inspection, the task of the decoder is to find the string of words that maximizes the likelihood of generating the observation. That is, what is the probability of these set of words generating said speech.

Perhaps children also have a statistical model of speech.
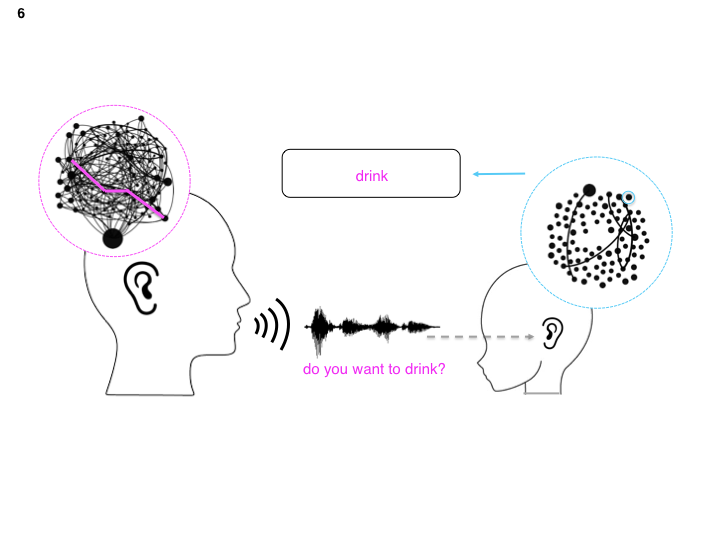
Now, we want to highlight the language representation that humans use when decoding (perceiving) speech. We use networks to represent language (complex system).
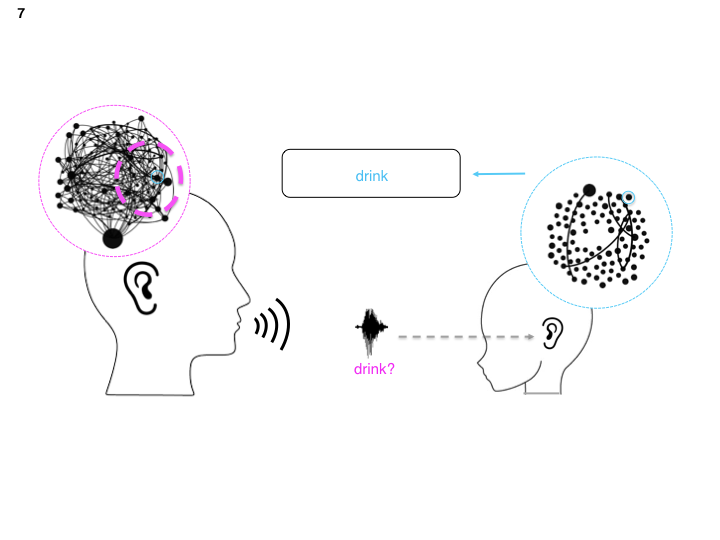
This allows us to highlight how the adult’s language network is much larger than a child’s. The interpretation here is that the child knows less words and the connections between these words aren’t as redundant or even efficient for navigating.

High-level messaging :)
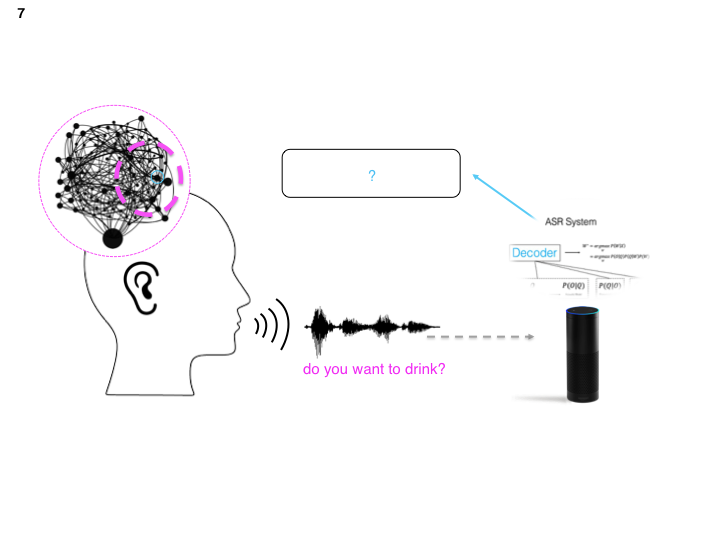
Okay, so what we want to do is see how an automatic speech recognition system will learn given a ton of child-directed speech. Basically, we swap the “typical” American child for Alexa to model both nature (implicit knowledge) and nurture (instruction by guardians).
Best,
EO