Week 41 (Extension)
Re-segmenting
A few weeks ago we noticed a discrepancy with the number of hours I calculated in each of the CHILDES age ranges.
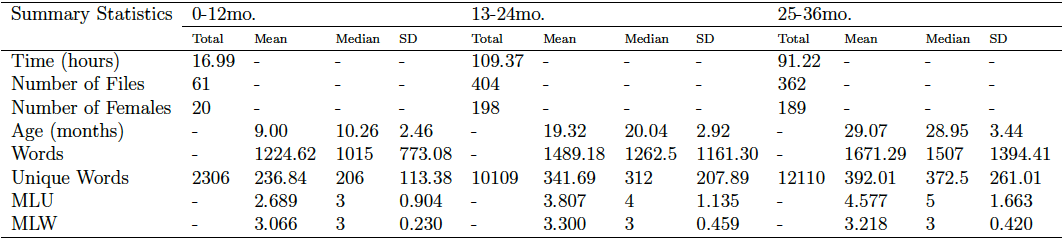
According to the table below Rebekah calculated, the number of hours in each of the age ranges should be:
0-12: 16.99 hrs
13-24: 109.37 hrs
25-36: 91.22 hrs
However, when I calculated the duration of each corpus when I resampled the audio segments down to 16 kHz I OBTAINED!!!:
0-12: 16.56 hrs
13-24: 260.91 hrs
25-36: 89.67 hrs
So, this prompted me to look at my segmentation method:
for index = 1:length(matches)
num = textscan(string(strrep(matches(index),'_', ' ')),'%f', 'Delimiter',' ');
num = num2cell(permute(num{1},[2,1]));
num = cell2mat(num);
st = num(1);
et = num(2);
if(st == 0)
st = st + 1;
end
% Get start and stop times from matches
startTime = round((st/1000)*Fs);
endTime = round((et/1000)*Fs);
if(endTime > length(input_signal))
endTime = length(input_signal);
end
startTime = max(startTime,1)
if(startTime > length(input_signal))
startTime = round(startTime - Fs);
end
segment = input_signal(startTime:endTime);
if(isempty(segment))
disp('audio file(s) does not exist');
AccumulatedTranscripts = [AccumulatedTranscripts; {thisBaseFileName}];
end
% Format name for output file
index = num2str(index);
index = insertBefore(index,index,'_');
outputFileName = strcat(index,'.wav');
outputFileName = strrep(thisBaseFileName,'.txt', outputFileName);
% Output audio file
audiowrite(outputFileName,segment, Fs);
end
Then, I saw the following lines:
% Get start and stop times from matches
startTime = round((st/1000)*Fs);
endTime = round((et/1000)*Fs);
if(endTime > length(input_signal))
endTime = length(input_signal);
end
startTime = max(startTime,1)
if(startTime > length(input_signal))
startTime = round(startTime - Fs);
end
segment = input_signal(startTime:endTime);
Dr. Brumberg gave me some advice on the code and, then I made the following changes:
startSample = (startTime/1000)*Fs;
startSample = max(startSample,1); % If start time is 0
endSample = (endTime/1000)*Fs;
segment = input_signal(floor(startSample):ceil(endSample));
And also added:
% Resample audio segment
[P,Q] = rat(16e3/Fs);
% Normalize audio
segment = segment/max(abs(segment(:)));
% Leave headroom
segment = segment * 0.9;
% Resample signal
resampled_signal = resample(segment,P,Q);
So, after the segments still make sure to resample back down to 16 kHz.
for index = 1:length(matches)
% Convert the timestamps from transcripts to numbers
% Note: the timestamps are in milliseconds
num = textscan(string(strrep(matches(index),'_', ' ')),'%f', 'Delimiter',' ');
num = num2cell(permute(num{1},[2,1]));
num = cell2mat(num);
startTime = num(1);
endTime = num(2);
% Use timestamps to segment audio file
startSample = (startTime/1000)*Fs;
startSample = max(startSample,1); % If start time is 0
endSample = (endTime/1000)*Fs;
segment = input_signal(floor(startSample):ceil(endSample));
if(isempty(segment))
disp('audio file(s) does not exist');
AccumulatedTranscripts = [AccumulatedTranscripts; {thisBaseFileName}];
end
% Resample audio segment
[P,Q] = rat(16e3/Fs);
% Normalize audio
segment = segment/max(abs(segment(:)));
% Leave headroom
segment = segment * 0.9;
% Resample signal
resampled_signal = resample(segment,P,Q);
% Construct the name for output audio segment
index = num2str(index);
index = insertBefore(index,index,'_');
outputFileName = strcat(index,'.wav');
outputFileName = strrep(thisBaseFileName,'.txt', outputFileName);
% Output audio file
audiowrite(outputFileName,resampled_signal,16e3);
end
Then, I tried resegmenting and resampling all the CHILDES files. This process took a bit, but I it was an opportunity to check out if the problem was actually with my segmentation method or some of the transcripts (error coding the timestamps). I ended up finding that my segmentation method was probably collecting more audio that it needed:
if(endTime > length(input_signal))
endTime = length(input_signal);
end
But also that some of the transcripts did have coding errors:
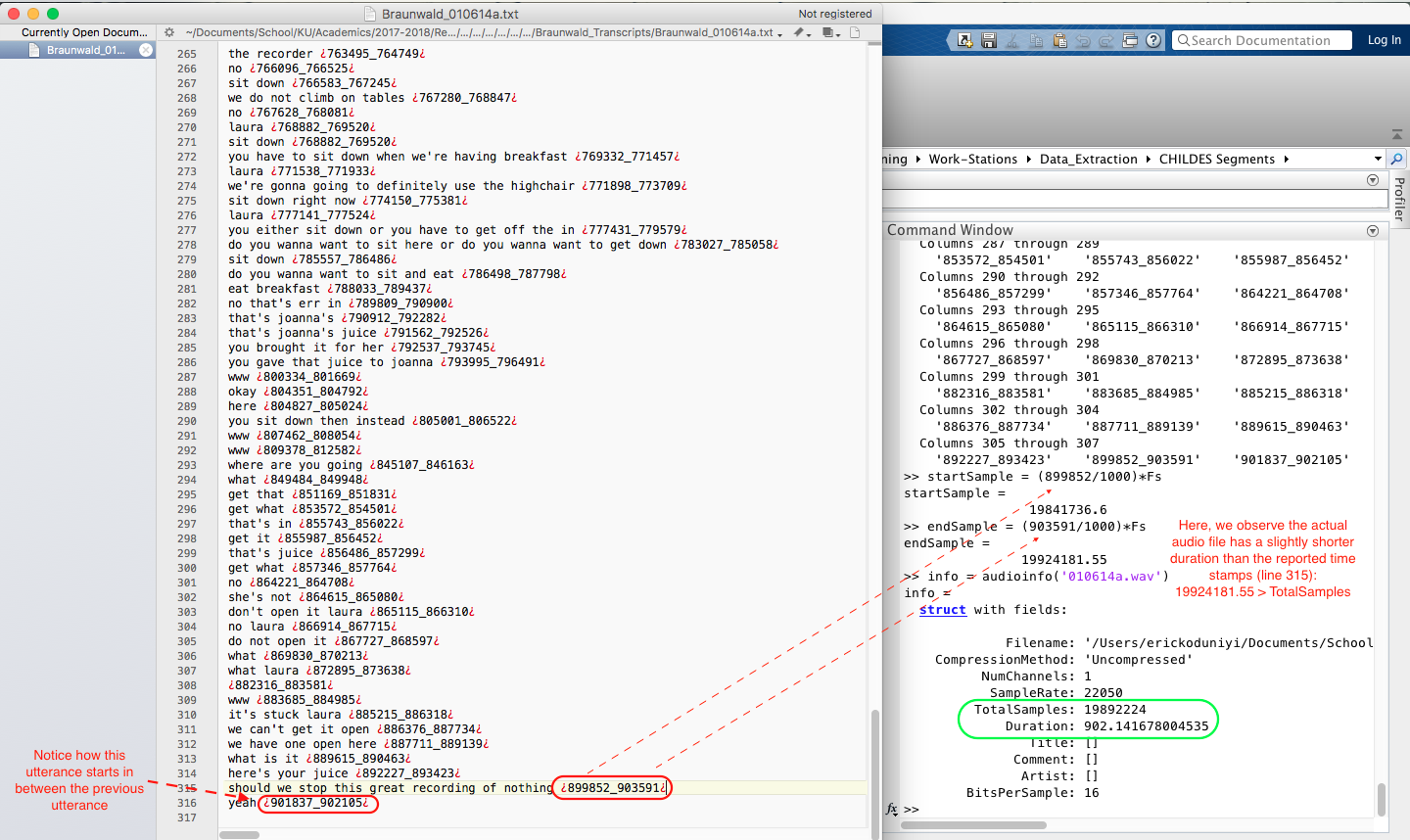
So, I ended up getting errors:
index exceeds matrix dimensions
Error in get_childes_segments (line 93)
segment = input_signal(floor(startSample):ceil(endSample))
When this error occurred it meant I had to get rid of the last two or last utterance/timestamps, which is fine.
Updating my segmentation method was actually helpful because I got to check if my segments really matched the length of time that the timestamps indicated. It also, helped me listen to some of the different sub copra again. Again, I noticed that they vary in sound quality. and noisiness, but also some of them are panned for the video. For example, listen to the first few seconds of the audio file from the Providence sub corpus. After resegmenting, resampling, and making the panning adjustments I can try recalculating the audio duration in the different CHILDES age ranges.
Voice activity detection
Trying to figure out a good way extract only the adult speech from audio segments. Because again, the recorded utterances are sometimes not only the parent’s utterance, but contain unnecessary silence, child speech, music, or speech is buried in background noise and so is unintelligible. But yeah, I need to create some threshold for the audio segments, which says if the audio segments contains the following: snr, some probability of speech, and child utterances, get rid of it. From there, I can actually see how many hours of speech I have left to train and test on.
Best,
EO