Week 42 (Extension)
Additional summary statistics
So, before I created a threshold I wanted to go through the resegmented audio files and get the snr values, so I can collect an average snr for each of the sub corpus and ages ranges. This will be one of my metrics for getting rid of the unusable audio files:
for k = 1 : totalNumberOfFiles
%% Go through each file
thisFolder = allFileInfo(k).folder;
thisBaseFileName = allFileInfo(k).name;
fullFileName = fullfile(thisFolder, thisBaseFileName);
[input_signal, Fs] = audioread(fullFileName);
r = mean(abs(hilbert(input_signal)))/(std(input_signal));
AccumulatedSNR = [AccumulatedSNR; {r}];
AccumulatedDuration = [AccumulatedDuration, {length(input_siganl)/Fs}];
end
So, I’ll end up with three list that I can use to calculate the average, median, and standard deviation for snr, samples, and duration respectively. Notice, I can calculate the average number of samples from the average number of duration. Once I have these calculated I can plot them to observe the nature of the data.
VoxForge corpus
Additionally, I wanted to go through the VoxForge transcripts and scrape the mean length utterance (MLU), mean length word (MLW), and the total number of words, and unique words:
for k = 1 : totalNumberOfFiles
%% Go through each file
thisFolder = allFileInfo(k).folder;
thisBaseFileName = allFileInfo(k).name;
fullFileName = fullfile(thisFolder, thisBaseFileName);
% Read in the transcript
% Note: fileText is a .txt file
fileText = textread(fullFileName,'%s','delimiter','\n');
% Go through each line
for i = 1:length(fileText)
utterance = extractAfter(fileText(i)," ");
str = strjoin(utterance);
matches = regexpi(str, '\w+');
N = numel(matches);
AccumulatedMLU = [AccumulatedMLU; {N}];
split_str = split(strtrim(erase(str,[".",","])));
words = strlength(split_str);
for j = 1:length(words)
AccumulatedWords = [AccumulatedWords, {split_str(j)}];
AccumulatedMLW = [AccumulatedMLW; {words(j)}];
end
end
end
Though, Rebekah already completed this for me…
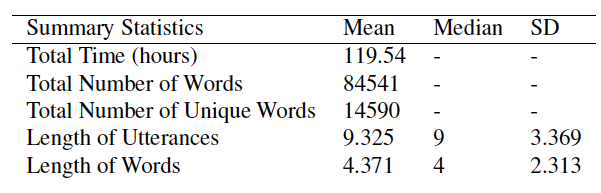
Again, the VoxForge corpus is supposed to represent typical adult speech, so the typical length of utterance and and typical length of word and thus we expect them on average to be longer.
Voice activity detection
Still trying to figure out a good way to set a threshold for the audio segments…In any case it would be useful to now start training on VoxForge and testing on some of the CHILDES data.
Best,
EO